




Rev Spotlight
Featured Posts

Rev vs. Otter: Which is Better for Your Productivity Needs?



Blog posts

Evidence Review: Discovery Analysis (Part 2)
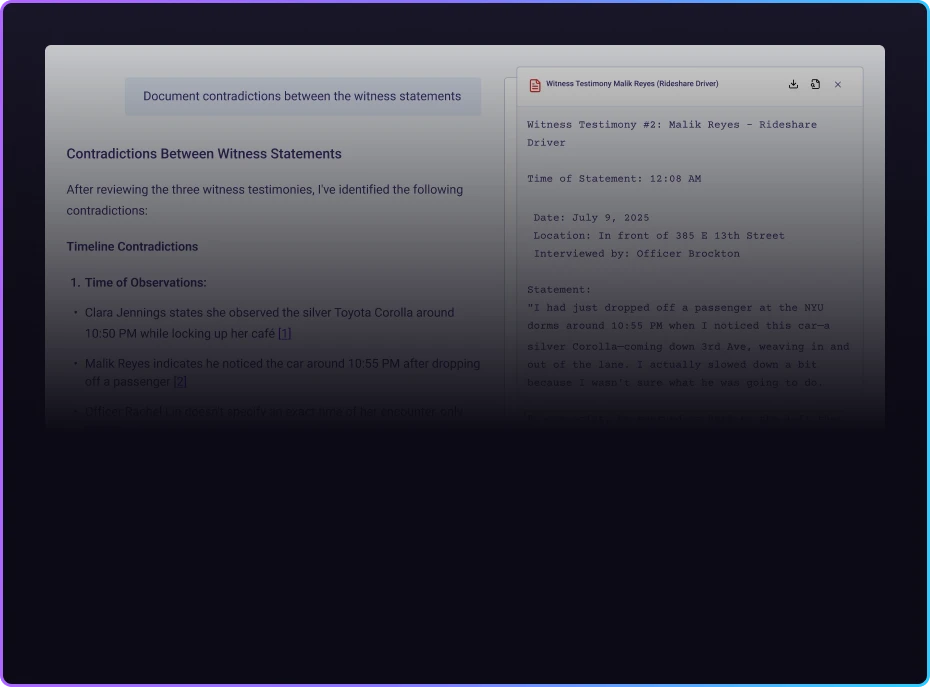
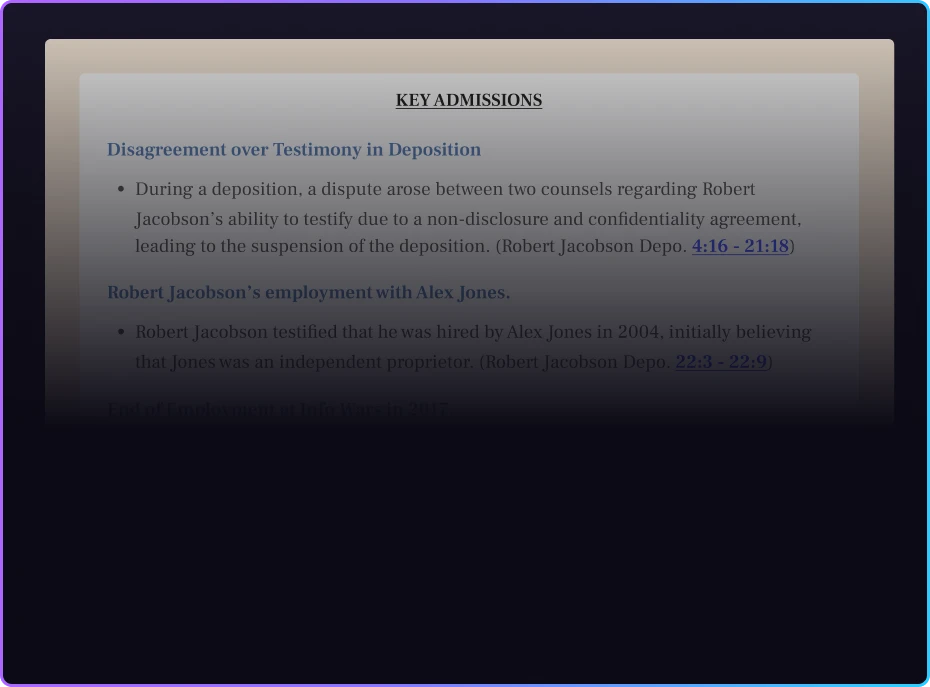
Learn how Rev Insights revolutionizes legal discovery by analyzing transcripts across multiple sources to uncover contradictions and discrepancies instantly.

Confidential Transcription: Protect the Record With Rev
Learn how to choose confidential transcription services that protect legal, medical, and corporate recordings. See how Rev keeps your sensitive data secure.

Evidence Review: Intake and Initial Review (Part 1)
Discover how Rev streamlines the intake and initial review phase of legal evidence by capturing audio, video, text, and live recordings in one secure workspace.

A Note from Our CEO: The Future of Rev
What started as a resource for journalists and researchers committed to uncovering the truth has grown into a powerful investigative platform. Hear from our CEO Jason on where we’re going next, and why it matters.
Free Transcription Tools That Make Your Life Easier
Explore Rev’s free transcription tools and see how to convert audio or video into text online—accurate, fast, and easy to use.
7 Best Free Speech-to-Text Apps for iOS
Rev’s guide to the 7 best free speech to text transcription apps for iOS covers everything from the new VoiceHub to Apple Voice Control and Dictanote.
How to Add Captions & Subtitles to Google Hangouts & Google Meet Recordings
Add even more value to every video. Learn how to add closed captions & subtitles to Google Hangouts & Google Meet recordings & meetings.
Subscribe to The Rev Blog
Sign up to get Rev content delivered straight to your inbox.